




I. Introduction▲
Autant pour un être humain, il est facile d'inventer des mots nouveaux, autant pour un ordinateur, ce n'est pas si simple que cela en à l'air. Il ne s'agit évidemment pas de fabriquer des suites de caractères purement aléatoires, qui seraient imprononçables, mais bien de produire des noms (de personnes, de lieux, d'espèces, etc.) ayant une certaine vraisemblance.
C'est un besoin assez connu dans l'univers des jeux de rôle où la multitude de personnages et de lieux fait qu'une génération procédurale peut soulager grandement la tâche du Maître du Jeu (dans le cas des jeux de rôle papier) ou des concepteurs (dans le cas des jeux de rôle informatiques).
Nous essayerons donc dans cette présentation de trouver une solution à cette génération aléatoire (mais vraisemblable) de noms.
Puisque nous aborderons le concept de chaînes de Markov qui ont des applications diverses, cet article peut éventuellement être utile aux personnes souhaitant une introduction à ces chaînes de Markov, indépendamment de la question de la génération aléatoire de noms.
Le langage utilisé pour illustrer les algorithmes sera TypeScript, un sur-ensemble de JavaScript avec typage et héritage. Une présentation de ce langage est disponible ici.
II. Elite▲
Elite est un jeu célèbre des années 1980 qui a posé les bases des mondes ouverts et de la génération procédurale. Parmi les nombreux éléments générés à chaque nouvelle partie, se trouve le nom des étoiles.
La génération du nom des étoiles dans Elite est très simple ce qui ne l'empêche pas d'être efficace. L'algorithme va piocher aléatoirement dans une liste prédéfinie, quatre paires de lettres (consonne puis voyelle ou inversement) formant ainsi quatre syllabes qui formeront le nom final.
Voici ce que pourrait donner l'implémentation en TypeScript :
function randNameElite(): string {
var pairs = "..lexegezacebiso"
"usesarmaindirea."
"eratenberalaveti"
"edorquanteisrion";
var pair1 = 2 * Math.floor(Math.random() * (pairs.length / 2));
var pair2 = 2 * Math.floor(Math.random() * (pairs.length / 2));
var pair3 = 2 * Math.floor(Math.random() * (pairs.length / 2));
var pair4 = 2 * Math.floor(Math.random() * (pairs.length / 2));
var name = "";
name += pairs.substr(pair1, 2);
name += pairs.substr(pair2, 2);
name += pairs.substr(pair3, 2);
name += pairs.substr(pair4, 2);
name = name.replace(/[.]/g, "");
return name;
} // randNameElitePour les plus curieux, le concepteur du jeu, Ian Bell, a mis en ligne une partie des sources du jeu Elite, en langage C.
Pour avoir un aperçu de cette génération de noms aléatoires d'étoiles, il est possible d'expérimenter le Générateur Aléatoire d'Univers présenté dans un autre sujet, enrichi de cette fonctionnalité, en passant la souris sur les divers lieux générés. En voici quelques exemples :
|
Bisosole |
|
Xesoleza |
|
Sosolege |
|
Bigecege |
|
Soxelebi |
Dans un contexte spatial où les noms des étoiles peuvent être très exotiques, l'algorithme d'Elite peut suffire, même s'il y a toujours la possibilité de raffiner. Cependant, pour d'autres contextes, comme celui de la génération de prénoms ou de noms de villes, les noms issus de l'algorithme d'Elite ne feraient pas longtemps illusion.
Pour cela, d'autres méthodes sont nécessaires.
III. Chaînes de Markov▲
III-A. Théorie▲
Une chaîne de Markov est un processus stochastique mettant en jeu un ensemble d'états et des probabilités de transitions entre ces états dont le but est de modéliser les phénomènes où certaines séquences d'états ont davantage de chances de se produire que d'autres.
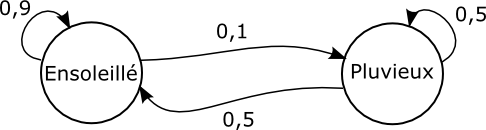
Sur le schéma ci-dessus, si le processus se trouve dans l'état Ensoleillé, alors il a 90 % de chances d'y rester (boucle) et 10 % de passer à l'état Pluvieux. Si le processus se trouve dans l'état Pluvieux, alors il a 50 % de chances d'y rester et 50 % de chances de passer à l'état Ensoleillé. Intuitivement, on devine que le processus aura tendance à enchaîner successivement davantage les états Ensoleillé que les états Pluvieux.
Une version animée de l'exemple précédent peut être visualisée sur le blog de Setosa.
L'utilisation de chaînes de Markov comporte en général trois grandes phases. La première consiste à générer un modèle probabiliste à un phénomène à partir de l'expérience. Par exemple, à partir de l'historique des relevés météorologiques, il est possible d'établir la probabilité de transition entre les différents temps (par exemple : ensoleillé, nuageux, pluvieux) à partir d'un temps donné en supposant que la météo du lendemain ne dépend que de la météo du jour concerné, sans influence des jours précédents.
La seconde phase consiste à appliquer ce modèle à partir d'une situation donnée pour prédire la probabilité des états futurs. Par exemple, à partir d'un modèle météorologique markovien, il est possible d'estimer la probabilité de beau temps et de mauvais temps en fonction de la météo du jour. Autre exemple, le PageRank de Google qui serait basé sur une chaîne de Markov, ne serait que la probabilité de transition vers une page donnée à partir d'une page quelconque.
Enfin, la troisième phase consiste à considérer le problème à l'envers qui est à partir d'une succession d'états, savoir si c'est une succession possible d'états dans une chaîne de Markov prédéfinie. Par exemple, à l'aide d'un modèle météorologique markovien, disons de la ville de Paris, il est possible d'analyser des relevés météorologiques sur une année et voir s'ils correspondent à une succession possible de temps à Paris. Selon les résultats, les relevés peuvent être déclarés compatibles avec la météo de Paris ou au contraire incompatibles ou improbables. En principe, un modèle météorologique markovien conçu pour Paris devrait déclarer comme incompatibles ou improbables les relevés météo de Tombouctou ou ceux d'Oslo et par contre accepter les relevés pris sur Paris. Notons que cette troisième phase s'inscrit plus généralement dans le domaine de la reconnaissance de formes où les chaînes de Markov sont notamment utilisées dans la reconnaissance vocale. Nous n'aborderons pas cette troisième phase dans cet article.
Aussi, une chaîne de Markov qui est à la base un objet mathématique fait appel à un certain formalisme, notamment celui de l'algèbre linéaire, que nous n'aborderons pas non plus ici. Pour avoir plus de développement sur les aspects théoriques des chaînes de Markov, le lecteur peut par exemple consulter le cours à ce sujet de Marc Lelage (INRIA/ENS).
III-B. Mise en œuvre▲
Il est possible de faire appel aux chaînes de Markov pour la génération aléatoire de noms dans la mesure où on peut voir cette génération aléatoire comme une sorte de prédiction réalisée à partir d'un modèle probabiliste que nous aurons préalablement construit à partir d'une liste de noms.
La première phase, l'élaboration du modèle probabiliste, consiste à calculer et à stocker les probabilités de transition d'une lettre à une autre. Pour cela, notons le début d'un nom de la liste par le symbole ^ qui sera le caractère de départ de n'importe quel nom et permettra d'initialiser la chaîne de Markov. De même, la fin d'un nom de la liste sera marquée par le symbole $. Par exemple le prénom jeanne, sera interprété dans notre modèle comme ^jeanne$.
Le but est de comptabiliser les occurrences de toutes les paires de lettres présentes dans la liste. Chaque paire représentant la transition de la première lettre de la paire vers la seconde. Par exemple la paire ab correspond à la transition entre la lettre a et la lettre b. Pour le cas d'une liste ne comportant que le nom ^jeanne$, on aurait les paires suivantes avec leur occurrence associée :
|
^j : 1 |
|
je : 1 |
|
ea : 1 |
|
an : 1 |
|
nn : 1 |
|
ne : 1 |
|
e$ : 1 |
Nous pouvons déjà interpréter la chaîne de Markov sous-jacente par rapport à ces occurrences :
- si on se trouve à l'état ^ (c'est-à-dire en début de mot), la lettre suivante doit forcément être un j ;
- si on se trouve à l'état j, la lettre suivante doit forcément être un e ;
- si on se trouve à l'état e, il y a 50 % de chances pour que la lettre suivante soit un a, et 50 % de chances que ce soit un $ (c'est-à-dire la fin d'un mot) ;
- si on se trouve à l'état a, la lettre suivante doit forcément être un n ;
- si on se trouve à l'état n, il y a 50 % de chances pour que la lettre suivante soit un n, et 50 % de chances que ce soit un e ;
- si on se trouve à l'état $, la chaîne de Markov est terminée.
Par exemple, cette chaîne de Markov pourrait produire les noms ^je$ ou encore ^jeannnnneane$.
En JavaScript/TypeScript, il est possible de stocker les occurrences dans l'ersatz de tableau associatif qu'est un objet. Si on reprend les occurrences précédentes, cela pourrait donner ceci en TypeScript :
transitions = {
"^j": 1
"je": 1
"ea": 1
"an": 1
"nn": 1
"ne": 1
"e$": 1
}Maintenant si on ajoute à la liste un nouveau nom, par exemple ^alexandre$, voici ce que donnerait les nouvelles occurrences de paires :
|
^j : 1 |
|
je : 1 |
|
ea : 1 |
|
an : 2 |
|
nn : 1 |
|
ne : 1 |
|
e$ : 2 |
|
^a : 1 |
|
al : 1 |
|
le : 1 |
|
ex : 1 |
|
xa : 1 |
|
nd : 1 |
|
dr : 1 |
|
re : 1 |
La nouvelle chaîne de Markov sous-jacente à ces occurrences nous indique entre autres que si on se trouve à l'état a, il y a 66 % (2/3) de chances pour que la lettre suivante soit un n, et 33 % (1/3) de chances que ce soit un l. Compte tenu d'un nombre d'états et de transitions plus élevé que précédemment, les mots possibles que peut produire cette chaîne de Markov sont plus nombreux.
Comme il ne serait pas possible de calculer à la main l'ensemble des occurrences de paires dans une liste un minimum consistante, une routine peut évidemment faire le travail à notre place. En TypeScript, cela pourrait donner ceci :
function computeTransitions(database: string[]): any {
var transitions = {};
for (var i = 0; i < database.length; i++) {
var word = database[i];
var prev = "^";
var next = "";
for (var j = 0; j < word.length; j++) {
next = word.substr(j, 1);
updateTransitions(transitions, prev, next);
prev = next;
} // for j
next = "$";
updateTransitions(transition,s prev, next);
} // for i
return transitions;
} // computeTransitions
function updateTransitions(transitions: Object, prev: string, next: string) {
var key = prev + next;
if (transitions.hasOwnProperty(key)) { // transition déjà existante
transitions[key]++;
}
else { // new transition
transitions[key] = 1;
}
} // updateTransitionsOn suppose que notre liste de noms, le paramètre database, est fournie sous la forme d'un tableau.
Pour l'exemple, nous pourrions considérer la liste de noms suivante :
var database = "agnès alain albert alexandre annabelle anne"
"baptiste béatrice benoit carl caroline cécile"
"christine christophe emmanuel emmanuelle emilie"
"éric eve frédéric gaspard henri henriette"
"isabelle jean jeanne jennifer joseph léa louis"
"marc marie marion maxime michel nathalie nicole"
"noémie olivia olivier patrick paul philippe"
"pierre rené robert sébastien sophie stéphane"
"stéphanie thierry".split(" ");Notez l'utilisation de la méthode split qui permet de convertir en tableau cette liste de noms séparés par des espaces.
Une chaîne de Markov étant donnée, l'algorithme pour générer aléatoirement une suite de lettres est assez intuitif et pourrait ressembler à ceci :
function randNameMarkov(transitions: Object): string {
var state = "^";
var result = "";
while (state != "$") {
var newLetter = markov(state, transitions);
result += newLetter;
state = newLetter;
} // while
return result.substr(0, result.length - 1); // supprime $ en fin de résultat
} // randNameMarkovoù la fonction markov renvoie une nouvelle lettre choisie en fonction des probabilités de transition à partir de l'état passé en paramètre. Dans cette fonction markov, pour un état donné, nous pouvons nous baser sur la fonction de répartition de ses transitions pour générer une nouvelle lettre à partir d'un nombre aléatoire compris entre 0 et 1. La fonction de répartition (cumulative distribution function en anglais) peut schématiquement être comparée à une table de résolution de lancers de dés dans les jeux de rôle.
|
d66 |
Localisation des dégâts |
|
11 à 14 |
Tête |
|
15 à 24 |
Bras gauche |
|
25 à 34 |
Bras droit |
|
35 à 52 |
Poitrine |
|
53 à 61 |
Jambe gauche |
|
62 à 66 |
Jambe droite |
|
Table de localisation des dégâts avec un d66 issue du jeu Heroes & Other Worlds |
Voici une implémentation en TypeScript de la fonction markov :
function markov(state: string, transitions: Object): string {
var cumDist = []; // Fonction de répartition
var sum = 0;
// Calcule la fonction de répartition des transitions de l'état
for (var key in transitions) {
if (transitions.hasOwnProperty(key) && // spécifique JavaScript
key.substr(0, state.length ) == state) {
sum += transitions[key];
var nextState = key.substr(state.length);
cumDist.push({ nextState: nextState, cumFreq: sum });
}
} // for key
// Choisit au hasard le prochain état
var random = Math.floor(sum * Math.random());
for (var i = 0; i < cumDist.length; i++) {
var nextState = cumDist[i].nextState;
var cumFreq = cumDist[i].cumFreq;
if (random < cumFreq) {
return nextState;
}
} // for i
return "";
} // markovOn notera qu'il serait préférable en termes de performance de stocker une bonne fois pour toutes la fonction de répartition des transitions pour chaque état, plutôt que de la reconstruire à chaque appel de la routine markov.
Le script exécutable de cette première approche est disponible ici.
En termes de résultats, voici ce qu'il est possible d'obtenir :
|
en |
|
ck |
|
chric |
|
riphendrivile |
|
llle |
|
mie |
|
an |
|
sébe |
|
st |
|
riolbéarle |
On remarque qu'à moins de créer des règles ad hoc, il n'est pas simple de générer des noms d'une longueur donnée. Aussi, les prénoms générés ne sont pas pour le moment très vraisemblables.
Un axe d'amélioration peut consister à enrichir le corpus de texte servant à la construction de la chaîne de Markov, le contenu de la variable database si on se réfère au code mentionné précédemment. En effet, plus le corpus « d'apprentissage » est riche, et plus il y a de chances que les « bonnes » transitions, les plus fréquentes et donc les plus vraisemblables, soient choisies par l'algorithme.
Cependant, cela peut ne pas suffire et c'est pour cela qu'il existe une variante aux chaînes de Markov.
III-C. Extension▲
Il est possible d'améliorer la qualité des noms générés par une chaîne de Markov en rajoutant une notion de mémoire. Dans les exemples jusqu'à présent, les transitions ne dépendaient que de l'état courant et ignoraient les états antérieurs, ce qui en langue française peut poser quelques soucis. Par exemple, après la séquence ch, il est courant d'avoir une voyelle, tout comme c'est le cas de la séquence qu.
Cet aspect peut être pris en compte en considérant non plus des transitions entre une lettre vers une autre, mais entre une paire de lettres vers une autre lettre. Par exemple pour l'exemple de la séquence ch suivie d'une voyelle on pourrait avoir les transitions suivantes :
|
ch -> a |
|
ch -> e |
|
ch -> i |
|
ch -> o |
|
ch -> u |
|
ch -> y |
Plus concrètement, cela revient à ne plus dénombrer les occurrences des paires de lettres dans une liste de noms, mais les occurrences de triplets de lettres (ou trigrammes). On parle alors de chaîne de Markov d'ordre 2, correspondant aux deux états nécessaires pour considérer une transition ; sachant que les chaînes de Markov simples sont des chaînes de Markov d'ordre 1 où un seul état, l'état courant, suffit pour connaître les probabilités de transition vers un nouvel état.
On remarque dès lors qu'il est possible de généraliser à un ordre quelconque afin d'améliorer la vraisemblance des noms générés, tout en ayant à l'esprit que le nombre de transitions possibles et donc à mémoriser (et à parcourir selon les implémentations), augmente exponentiellement à mesure que l'ordre est élevé. Aussi, autre aspect pernicieux, à mesure que l'ordre est élevé, la vraisemblance des noms générés s'accroît au point qu'à un moment les noms peuvent ne plus être que des noms déjà existants, sans nouveauté. Ce revers qualitatif est assez analogue au phénomène du surapprentissage dans le domaine de l'intelligence artificielle. Mais c'est un autre sujet.
Sur la base des prénoms français, une chaîne de Markov d'ordre 4 ne génère pratiquement pas de noms originaux, alors qu'une chaîne de Markov d'ordre 3 donne des résultats plus intéressants.
On peut trouver une démonstration en ligne des chaînes de Markov sur les corpus des villes françaises (ordre 4) et des villes britanniques (ordre 4), ainsi que sur les prénoms français (ordre 3).
Voici un résultat possible issu de la démonstration en ligne avec les prénoms français :
|
Stéphaël |
|
Cécile |
|
Émille |
|
Armelle |
|
Léonatienne |
|
Ariste |
|
Marthée |
|
Henri |
|
Corin |
|
Emence |
On constate en premier lieu que la vraisemblance ici est meilleure qu'avec une chaîne de Markov simple sur un corpus d'apprentissage réduit. On note aussi que l'algorithme reprend des prénoms déjà existants (e.g. Cécile), mais fait preuve tout de même d'un peu d'imagination (e.g. Stéphaël, Léonatienne) et c'est ce que nous souhaitions.
À noter que le code source de la démonstration en ligne est disponible sur mon compte GitHub.
IV. Conclusion▲
Nous venons de voir une méthode très simple de génération aléatoire de noms, celle du jeu Elite, basée sur une suite de paires prédéfinies et équiprobables, et une autre méthode, celle des chaînes de Markov, légèrement plus sophistiquée, et qui fournit des résultats plus généraux, applicables à divers contextes y compris celui de la génération aléatoire de phrases, à condition de disposer d'un corpus initial d'exemples de taille et de qualité suffisantes.
Il existe de nombreuses pistes pour améliorer les résultats des chaînes de Markov présentées ici. Par exemple, nous pourrions contraindre l'algorithme à produire des noms d'une longueur déterminée. En plus des transitions issues du corpus initial d'exemples, nous pourrions aussi imposer des contraintes sur la structure même des séquences possibles via l'introduction de grammaires formelles.
Enfin, les chaînes de Markov présentées succinctement dans cet article pour la génération aléatoire de noms peuvent également être utilisées pour d'autres aspects d'un jeu vidéo, comme en intelligence artificielle.
IV-A. Remerciements▲
Je remercie LittleWhite pour la relecture technique ainsi que Claude Leloup pour la relecture orthographique de cet article.
Les commentaires et les suggestions d'amélioration sont les bienvenus, alors, après votre lecture, n'hésitez pas. Commentez1.